Instagram 크롤러 + 딥러닝 공부(CNN) 성능 높이기 실험
캡스톤 디자인프로젝트A의 우리 팀 주제는 딥러닝 기반 해시태그 필터링이다.
일단 초기에 생각하기로는 인스타그램, 페이스북 등등의 SNS를 사용하다보니 맛집을 검색해도 셀카가, 운동을 검색해도 셀카+ 노출 사진, 여행을 검색해도 그저 셀카..로 무성한 검색기능이 뭔가 잘 못 되었단 생각이 들었다.
검색을 하다보면 셀카만이 문제가 아니다.
검색어와 관련이 없는 게시물들이 온통 섞여서 결과에 나타나니까.. 필요한 정보를 얻기 어려웠다.
인스타그램 크롤러를 만들다 보니 왜 이렇게 되는지 알았다..
일단 프로젝트는 3가지의 필터링을 거친다.
1. 검색어와 게시물의 사진이 관련이 있는가?
2. 게시물의 해시태그 끼리의 연관성이 있는가?
3. 검색어와 게시물에 사용된 해시태그간의 연관성이 있는가?
초기에는 인스타그램, 트위터, 페이스북, 유튜브를 모두 통합 검색할 수 있게 하였으나 일단은 가장 보편적이기도 하고,
프로젝트의 주제와도 잘 부합한다고 판단한 인스타그램에 집중하기로 했다.
멘토링을 거치면서 또 지도교수님과의 면담을 하면서 보니.. 일단 데이터를 모으는 것이 급선무였다.
CNN을 공부하다 보니 몇 십개, 몇 백개로는 택도 없고 2000개로도 학습량이 넉넉하다고 생각하지 않았다.
일단 검색어를 입력하면 검색결과의 게시물을 크롤링해 오는 식으로 구상해야한다.
크롤러를 처음 만들어서 이게 정확히 어떤 원리인지, 어떤 라이브러리의 어떤 함수를 사용하는지도 몰라서 구글링을 통해 정보를 많이 얻었다.
Part 1. 인스타그램 링크, 본문, 해시태그, 작성일, 이미지, 영상, 좋아요 개수, 장소 크롤링
첫번째 크롤러 참고자료
인스타그램 해시태그 크롤링 및 분석 - 2
지난 번 내용과 이어서 해시태그와 좋아요, 날짜등을 가져오는 함수를 만들어보도록 하겠습니다. SCROLL_PAUSE_TIME = 2.0 post_link = [] while True: pageString = driver.page_source # page_source : 현재 렌..
hansuho113.tistory.com
www.youtube.com/watch?v=j_BW5vNrcxA
이때 사용한 방식은 selenium에서 scroll을 통해 모든 게시물의 링크를 가져오고, 그 링크를 하나씩 읽어서 게시물을 퍼왔다.
처음에는 로그인을 하고, 검색 결과 화면을 링크를 통해 이동, 링크 가져오기, 링크로 게시물 읽기 방법이었다.


실제 코드
import pandas as pd
import numpy as np
import selenium
from selenium import webdriver
from bs4 import BeautifulSoup as bs
from urllib.request import urlopen, Request
import urllib.parse
import time
from selenium.webdriver.common.keys import Keys
from tqdm import notebook
import warnings
# Create Empty List & Parameter Setting
print("start")
path = 'C:/Users/kahyu/Desktop/crawling/chromedriver'
driver = webdriver.Chrome(path)
SCROLL_PAUSE_TIME = 1.0
post_link = []
popularPost_len = []
id_list = []
like_list = []
tag_list = []
link_list = []
num_of_post=0
ID = ''
PW = ''
keyword=input("검색어를 입력하세요:")
#로그인 기능
def login(id,pw):
url = 'http://www.instagram.com'
driver.get(url)
driver.implicitly_wait(5)
driver.find_element_by_name('username').send_keys(id) # id 입력
elem_pw = driver.find_element_by_name('password') # pw 입력
elem_pw.send_keys(pw)
elem_pw.submit()
driver.implicitly_wait(5) # 파싱될 때까지 5초 기다림 (미리 완료되면 waiting 종료됨)
driver.find_element_by_class_name('cmbtv').click() # 비밀번호 저장하지 않음
driver.implicitly_wait(5)
driver.find_element_by_xpath(
'/html/body/div[4]/div/div/div/div[3]/button[2]').click()
#검색결과 창으로 이동
def move_to_search():
search=urllib.parse.quote(keyword)
url='https://www.instagram.com/explore/tags/'+str(search)+'/'
driver.get(url)
driver.implicitly_wait(10) # 파싱될 때까지 5초 기다림 (미리 완료되면 waiting 종료됨)
#스크롤 하면서 링크 얻기
def scroll_crawling():
post_link.clear()
popularPost_len.clear() # 이전 작업기록이 남아있을 수 있으므로 clear해줌
start = time.time()
while True:
pageString = driver.page_source
bsObj = bs(pageString, 'lxml')
temp_postlink = []
for postline in bsObj.find_all(name='div', attrs={"class":"Nnq7C weEfm"}):
a_len = len(postline.select('a'))
popularPost_len.append(a_len)
# 인스타그램 게시물은 행별로 최대 3개까지 확인할 수 있는데, 최근게시물이나 마지막 게시물은 1,2개가 나올 수도 있어서 len 지정
for post in range(a_len):
item = postline.select('a')[post]
link = item.attrs['href']
if link not in post_link: # 스크롤을 내리고 중복된 것을 제거하지 않고 누적시키기 때문에 없는 것만 추가
post_link.append(link)
temp_postlink.append(link)
count = len(temp_postlink)
#링크의 게시물 읽어오기
for i in range(len(temp_postlink)):
req = Request("https://www.instagram.com" + temp_postlink[i], headers={'User-Agent': 'Mozila/5.0'})
postpage = urlopen(req).read()
post_body = bs(postpage, 'lxml', from_encoding='utf-8-')
post_core = post_body.find('meta', attrs={'property': "og:description"})
contents = post_core['content']
# 개별 링크 리스트
link_list.append("https://www.instagram.com" + temp_postlink[i])
# 좋아요
try:
likes = int(contents[: contents.find(' Likes, ')]) # Likes 문자열 앞에 있는 좋아요 개수 추출
except:
likes = 0 # 좋아요 가 아니라 조회수로 표시되는 경우도 있어 이런 경우는 0으로 표시
like_list.append(likes)
# 개별 계정
if "@" and ")" in contents:
personal_id = contents[contents.find("@") + 1: contents.find(")")]
elif "@" and ":" in contents:
personal_id=contents[contents.find("@")+1:contents.find(":")]
elif "shared a post on Instagram" in contents:
personal_id = contents[contents.find("@") + 1: contents.find('shared a post on Instagram')]
elif "shared a photo on Instagram" in contents:
personal_id = contents[contents.find("@") + 1: contents.find('shared a photo on Instagram')]
elif "@" and ")" not in contents and "on Instagram" in contents:
personal_id = contents[contents.find("@") + 1: contents.find('on Instagram')]
else:
personal_id = contents[1: contents.find(' posted on')]
id_list.append(personal_id)
# 해시태그
tag_list.append([])
for tag_content in post_body.find_all('meta', attrs={'property': "instapp:hashtags"}):
hashtags = tag_content['content'].rstrip(',')
tag_list[-1].append(hashtags)
count -= 1
last_height = driver.execute_script('return document.body.scrollHeight') # 자바스크림트로 스크롤 길이를 넘겨줌
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # selenium에서 scroll 기능 사용
time.sleep(SCROLL_PAUSE_TIME)
# 프로세스 자체를 지정시간동안 기다려줌(무조건 지연)
# driver.implicitly_wait(SCROLL_PAUSE_TIME)
# 브라우저 엔진에서 파싱되는 시간을 기다려줌(요소가 존재하면 지연없이 코드 실행)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
# driver.implicitly_wait(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
else:
last_height = new_height
continue
login(ID,PW)
move_to_search()
scroll_crawling()
print('총 {0}개의 게시글을 수집합니다.'.format(len(post_link)))
insta_dict = {
'계정':id_list,
'좋아요':like_list,
'해시태그':tag_list,
'링크':link_list}
df = pd.DataFrame(insta_dict)
now=time.strftime('%m%d_%H_%M',time.localtime(time.time()))
df.to_csv(keyword+'_'+now+'.csv',encoding='utf-8-sig')
이렇게 잘 되던 크롤러가.. 다시 돌려보니 에러를 띄우면서 아무 일도 하지 않는 것이다..

위 에러를 구글링해보니 아이폰 인식 문제만 왕창 나오고 일단 시스템에 부착된 장치 자체가 없었기 때문에 해결할 수가 없었다. 저 에러 자체는 크롬 드라이버의 문제인가 싶어서 크롬 자체를 다시 깔아보기도 하고 코드를 한줄한줄 검토하기도 했는데 계속 에러가 나서 처음부터 아예 다른 방식으로 시도해보기로 했다.
(나중에 알고보니 크롬이 자동 업데이트를 해서 87 버전이 되었고, 크롬 드라이버는 86버전이어서 발생한 문제였다..;;)
개선해야할 부분
1. 게시물의 링크를 모두 가져오고->리스트에 넣고-> 리스트를 읽어서 게시물을 읽어오는 과정이 단순해 졌으면 좋겠다.
=> 게시물의 직접 링크를 이용하지 않고 검색시 첫 게시물을 클릭, 버튼을 이용해 이동하기로 수정
2. 게시물의 해시태그만 가져오는 것은 좋으나, 데이터 수집단계에서 정보를 거르고 가져오는 것은 권장하지 않는다(@멘토링)
=> 해시태그 추출을 하되, 기존 게시물의 글도 함께 저장
3. 게시물의 링크를 받고, 이미지와 영상을 링크로 가져와 학습시 이용할 수 있어야 한다.
<- 이미지와 영상을 일단 로컬에라도 저장해둘까 하였으나 메모리 문제, 추후 재 접속하고 싶을때를 고려해 링크로 저장해 파일로 쓰도록 하였다.
두번째 크롤러 참고자료
인스타그램 '사당맛집' 크롤링
인스타그램 크롤링을 통해 현재 내가 거주하고 있는 사당의 맛집 데이터를 수집해 보았다.검색어: '사당맛집'
velog.io
인스타그램 해시태그 크롤링(1)
준비 -운영체제 : Windows 10 -언어 : Python -웹 드라이버 : chromedriver.exe 프로그램 실행 과정 1. 인스타그램 해시태그를 크롤링합니다. 2. 검색어를 입력하면 검색어에 관한 게시물의 작성자 ID와 해시
yeowool0217.tistory.com
특히 두번째 자료를 유용하게 사용하였다.
위의 수정사항을 반영해 만든 결과는 다음과 같다.

일부 한글 자모음이 분리되는 현상, 사진 링크가 모두 동일하게 기록되었다.
자모음이 분리되는 현상은
import unicodedata
content=unicodedata.normalize('NFC',content_raw)이를 추가함으로써 해결할 수 있었다.
사진 링크가 모두 동일하게 기록되는 부분은 (참고로 동영상 링크 부분은 모두 제대로 기록되었다.) 원인을 찾기가 어려웠는데 이는 크롤러를 찬찬히 살펴보다가 해결할 수 있었다.
#1. 링크 주소 가져오기
try:
link= soup.find("a", {"class": "c-Yi7"}).attrs['href']
except:
link='NULL'
tmp_img=[]
tmp_vid=[]
while(1):
time.sleep(1)
pageString = driver.page_source
soup = BeautifulSoup(pageString, "lxml")
try:
videos= soup.find("video", {"class": 'tWeCl'}).attrs['src']
tmp_vid.append(videos)
except:
imgs = soup.select('img')[1]
imgs = imgs.attrs['src']
if imgs:
tmp_img.append(imgs)
else:
imgs = imgs.attrs['srcset']
tmp_img.append(imgs)
try :
driver.find_element_by_class_name("coreSpriteRightChevron").click()
except NoSuchElementException :
break
기존 코드를 살펴보면 이렇게 다음 게시물로의 버튼, 게시물 내에서 다음 사진으로의 버튼을 누르면서 링크를 한번에 받아왔다. 그리고 img의 2번째 항목을 받아와서 링크로 저장했는데 그 상태에서 f12를 통해 살펴보면
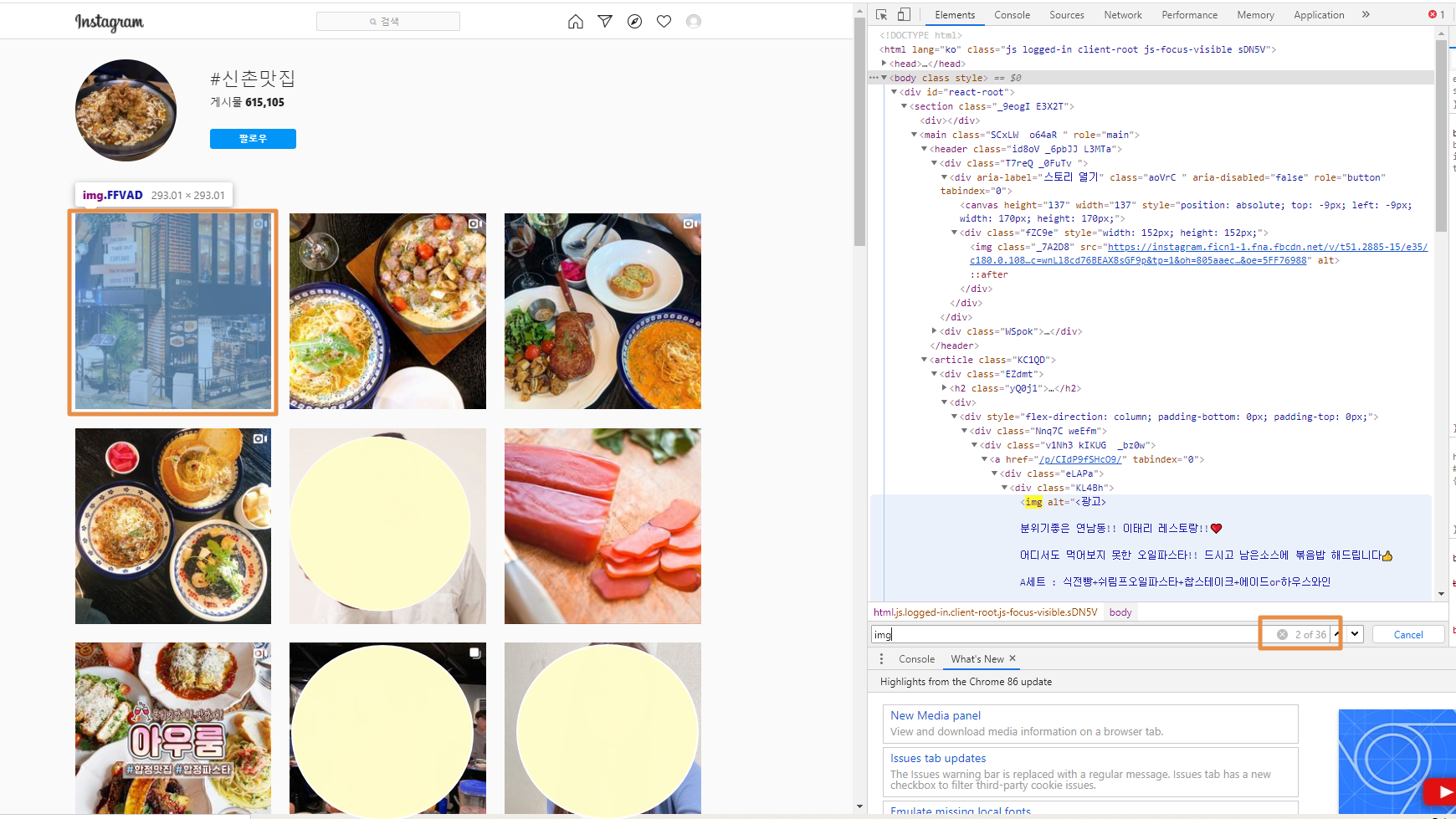
항상 검색 결과의 첫번째 게시물 사진을 받아오게 된다.
게시물을 클릭하고 넘어가도 2번째 img src는 동일하다.
이를 해결한 방법은 위의 link_list, 즉 게시물의 고유 링크를 담아둔 리스트를 이용하는 것이다.
다음 게시물로의 버튼 만을 이용해 link_list를 완성하고
for 문을 이용해 고유 링크로 이동-> 그 다음 게시물 내에서의 이동을 통해 사진 img src를 저장한다.
즉 이미지와 동영상 src를 가장 마지막에 추가하는 식으로 분리하였다.
결과는 다음과 같다

이렇게 크롤러를 완성했다.
전체 코드
import time
import unicodedata
from selenium.common.exceptions import NoSuchElementException
import insta_url
link_list=[]
like_list=[]
content_list=[]
tag_list=[]
date_list=[]
place_list=[]
src_img_list=[]
src_vid_list=[]
flag=0
#함수 작성
def insta_searching(word): #word라는 매개변수를 받는 insta_searching 이라는 함수 생성
url = 'https://www.instagram.com/explore/tags/' + word
return url
#첫번째 게시물 찾아 클릭 함수 만들기
import time
def select_first(driver):
first = driver.find_element_by_css_selector('div._9AhH0')
#find_element_by_css_selector 함수를 사용해 요소 찾기
first.click()
time.sleep(3) #로딩을 위해 3초 대기
#본문 내용, 작성 일시, 위치 정보 및 해시태그(#) 추출
def get_content(driver):
# 현재 페이지의 HTML 정보 가져오기
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
#1. 링크 주소 가져오기
try:
link= soup.find("a", {"class": "c-Yi7"}).attrs['href']
except:
link='NULL'
# 2. 본문 내용 가져오기
try: #여러 태그중 첫번째([0]) 태그를 선택
content_raw = soup.select('div.C4VMK > span')[0].text
content=unicodedata.normalize('NFC',content_raw)
time.sleep(1)
#첫 게시글 본문 내용이 <div class="C4VMK"> 임을 알 수 있다.
#태그명이 div, class명이 C4VMK인 태그 아래에 있는 span 태그를 모두 선택.
except:
content = ' '
# 3. 본문 내용에서 해시태그 가져오기(정규표현식 활용)
tags = re.findall(r'#[^\s#,\\]+', content) # content 변수의 본문 내용 중 #으로 시작하며, #뒤에 연속된 문자(공백이나 #, \ 기호가 아닌 경우)를 모두 찾아 tags 변수에 저장
# 4. 작성 일자 가져오기
try:
date = soup.select('time._1o9PC.Nzb55')[0]['datetime'][:10] #앞에서부터 10자리 글자
except:
date = ''
# 5. 좋아요 수 가져오기
try:
like = soup.select('div.Nm9Fw > button')[0].text[4:-1]
except:
like = 0
# 6. 위치 정보 가져오기
try:
place = soup.select('div.JF9hh')[0].text
except:
place = ''
# 7. 수집한 정보 저장하기
link_list.append("https://www.instagram.com"+link)
content_list.append(content)
like_list.append(like)
tag_list.append(tags)
date_list.append(date)
place_list.append(place)
def move_next(driver):
right = driver.find_element_by_css_selector('a._65Bje.coreSpriteRightPaginationArrow')
right.click()
time.sleep(4)
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import re
#1. 크롬으로 인스타그램 - 검색
driver = webdriver.Chrome("./chromedriver.exe")
search = input('검색어를 입력하세요: ')
word=str(search)
url = insta_searching(word)
target=int(input('크롤링할 게시물 수: '))
#2. 로그인 하기
id=input("아이디 입력: ")
pw=input("비밀번호 입력: ")
lurl = 'http://www.instagram.com'
driver.get(lurl)
driver.implicitly_wait(5)
driver.find_element_by_name('username').send_keys(id) # id 입력
elem_pw = driver.find_element_by_name('password') # pw 입력
elem_pw.send_keys(pw)
elem_pw.submit()
driver.implicitly_wait(5) # 파싱될 때까지 5초 기다림 (미리 완료되면 waiting 종료됨)
driver.find_element_by_class_name('cmbtv').click() # 비밀번호 저장하지 않음g
driver.implicitly_wait(5)
driver.find_element_by_xpath(
'/html/body/div[4]/div/div/div/div[3]/button[2]').click()
#3. 검색페이지 접속하기
driver.get(url)
time.sleep(4)
#4. 첫번째 게시글 열기
select_first(driver)
time.sleep(1)
#여러 게시물 크롤링하기
#크롤링할 게시물 수
for i in range(target):
data = get_content(driver) #게시물 정보 가져오기
m=i+1
print(str(m)+" 번째 게시물")
move_next(driver)
for i in link_list:
myurl=i
driver.get(myurl)
tmp_img=[]
tmp_vid=[]
videos=' '
imgs=' '
while(1):
time.sleep(4)
pageString = driver.page_source
soup = BeautifulSoup(pageString, "lxml")
try:
videos= soup.find("video", {"class": 'tWeCl'}).attrs['src']
tmp_vid.append(videos)
except:
imgs = soup.select('img')[1]
imgs = imgs.attrs['src']
if imgs:
tmp_img.append(imgs)
else:
imgs = imgs.attrs['srcset']
tmp_img.append(imgs)
try :
driver.find_element_by_class_name("coreSpriteRightChevron").click()
time.sleep(2)
except NoSuchElementException :
break
src_img_list.append(tmp_img)
src_vid_list.append(tmp_vid)
print("크롤링 완료")
import pandas as pd
from selenium.common.exceptions import NoSuchElementException
from time import sleep
insta_dict = {
'link':link_list,
'content':content_list,
'tags':tag_list,
'date':date_list,
'place':place_list,
'like':like_list,
'img':src_img_list,
'video':src_vid_list
}
df= pd.DataFrame(insta_dict)
now=time.strftime('%m%d_%H_%M',time.localtime(time.time()))
df.to_csv(word+'_'+now+'.csv',encoding='utf-8-sig')
print("파일 저장 완료")
마지막 부분에 아래 코드를 추가하면 '광고'라는 문구를 포함한 게시물을 포함한 행을 데이터프레임에서 삭제할 수 있다.
df_ad = pd.DataFrame(insta_dict)
df=df_ad[~df_ad.content.str.contains("광고")]
실행화면

크롬 드라이버를 이용해 자동으로 진행


크롤러를 이용하면서..
왜 인스타는 이미지와 검색어의 관련성이 없는데도 검색 결과에 노출시킬까? 에 대한 약간의 해답을 찾을 수 있었다.

인스타그램은 이미지를 인식하기는 하나 사람, 셀카, 음식, 바다 등의 큰 카테고리로만 구분할 뿐이고
이미지 분석 결과와 검색어의 연관성을 검색 결과에 나누어 반영하지 않는 것으로 보인다.
(그렇지 않고서야 신촌 맛집을 검색했는데 셀카를 인기 게시물로 노출 시키지는 않을 것이다..)
또한 직접 크롤링을 해보니 광고 게시물이 정말 많음을 확인 할 수 있었다.

대놓고 광고인 게시물, 신촌 맛집을 검색했음에도 나오는 네일 광고, 속눈썹 연장 등 뷰티 게시물등 관련 없는 게시물이 많아서 프로젝트의 필요성을 더욱 느낄 수 있었다 :-)
Part 2. CNN 모델 최적화 - 시계열 데이터를 이용
일단 CNN모델에 대한 개념이 필요하다고 생각해 딥러닝에 대한 공부를 했다.
아래는 스터디에 사용한 발표 자료 중 하나이다.
CNN 모델을 사용할지 RNN 모델을 사용할지 아직 확정적인 것은 아니나 일단 데이터 전처리를 연습해보고, 성능 최적화를 시도해 보았다.
%tensorflow_version 2.x
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import StratifiedShuffleSplit
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten, Convolution1D, Dropout,Conv1D,MaxPooling1D
from keras.optimizers import SGD
from keras.utils import np_utils
from tensorflow.keras.layers import Conv2D
import os
x=pd.read_csv('/content/drive/My Drive/Colab Notebooks/NATOPS/X1_TRAIN.csv')
y=pd.read_csv('/content/drive/My Drive/Colab Notebooks/NATOPS/Y1_TRAIN.csv')
z=pd.read_csv('/content/drive/My Drive/Colab Notebooks/NATOPS/Z1_TRAIN.csv')
#x,y 에 라벨링 제거
x=x.drop(['classAttribute'],axis=1)
y=y.drop(['classAttribute'],axis=1)
length=len(x)
df_train=pd.DataFrame()
df_train=pd.concat([x,y,z],axis=1,ignore_index=True)
df_train.rename(columns={153:'attribute_wr'},inplace=True)
x=pd.read_csv('/content/drive/My Drive/Colab Notebooks/NATOPS/X1_TEST.csv')
y=pd.read_csv('/content/drive/My Drive/Colab Notebooks/NATOPS/Y1_TEST.csv')
z=pd.read_csv('/content/drive/My Drive/Colab Notebooks/NATOPS/Z1_TEST.csv')
#x,y 에 라벨링 제거
x=x.drop(['classAttribute'],axis=1)
y=y.drop(['classAttribute'],axis=1)
length=len(x)
df_test=pd.DataFrame()
df_test=pd.concat([x,y,z],axis=1,ignore_index=True)
df_test.rename(columns={153:'attribute_wr'},inplace=True)
def encode(train):
label_encoder = LabelEncoder().fit(train.attribute_wr)
labels = label_encoder.transform(train.attribute_wr)
classes = list(label_encoder.classes_)
train = train.drop(['attribute_wr'], axis=1)
return train, labels, classes
df_train, labels, classes = encode(df_train)
def encode_test(test):
label_encoder = LabelEncoder().fit(test.attribute_wr)
labels = label_encoder.transform(test.attribute_wr)
classes = list(label_encoder.classes_)
test = test.drop(['attribute_wr'], axis=1)
return test,labels, classes
df_test, y_test,classes_test=encode_test(df_test)
scaler=StandardScaler().fit(df_train.values)
scaled_train=scaler.transform(df_train.values)
scaled_test=scaler.transform(df_test.values)
X_test=scaled_test
# split train data into train and validation
sss = StratifiedShuffleSplit(test_size=0.1, random_state=23)
for train_index, valid_index in sss.split(df_train, labels):
X_train, X_valid = scaled_train[train_index], scaled_train[valid_index]
y_train, y_valid = labels[train_index], labels[valid_index]모델부분은 하나의 요소를 변화시키되, 나머지 요소들은 통제한 상태에서 정확도와 학습시간을 측정하였다.
model = Sequential()
model.add(Conv1D(filters=256,kernel_size=12,strides=1, input_shape=(nb_features, 3)))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dropout(0.4))
model.add(Dense(nb_class))
model.add(Activation('softmax'))
y_train = np_utils.to_categorical(y_train, nb_class)
y_valid = np_utils.to_categorical(y_valid, nb_class)
y_test=np_utils.to_categorical(y_test,nb_class)
sgd = SGD(lr=0.01, nesterov=True, decay=1e-6, momentum=0.9)
model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
from datetime import datetime
dt = datetime.now()
start=dt
print(start)
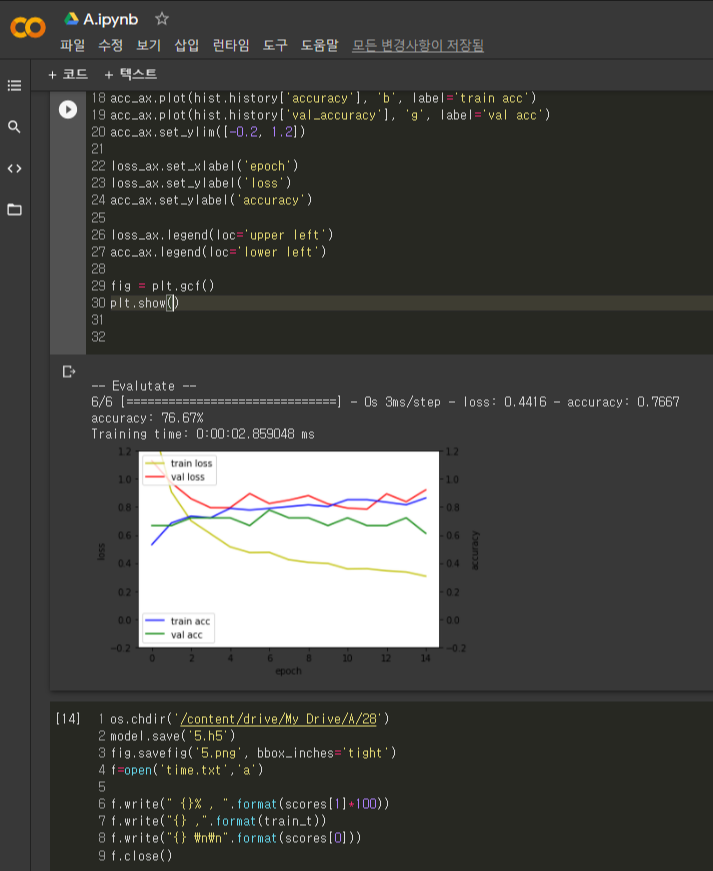
hist=model.fit(X_train_r, y_train,validation_data=(X_valid_r,y_valid), epochs=15, batch_size=5)
dt = datetime.now()
end=dt
print(end)
train_t=end-start
from matplotlib import pyplot as plt
# 모델 평가
print('\n-- Evalutate --')
scores = model.evaluate(X_test_r, y_test, verbose=1)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1] * 100))
print("Training time: {} ms".format(train_t))
# 학습과정 그래프
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.plot(hist.history['loss'], 'y', label='train loss')
loss_ax.plot(hist.history['val_loss'], 'r', label='val loss')
loss_ax.set_ylim([-0.2, 1.2])
acc_ax.plot(hist.history['accuracy'], 'b', label='train acc')
acc_ax.plot(hist.history['val_accuracy'], 'g', label='val acc')
acc_ax.set_ylim([-0.2, 1.2])
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuracy')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
fig = plt.gcf()
plt.show()


대략 80 번의 실험을 시행하였는데 이를 엑셀 파일로 정리한 결과는 다음과 같다.
위 실험은 동작 데이터는 오른쪽과 왼쪽의 엄지, 손목, 팔꿈치, 손에 3D센서를 부착해 6가지 행동을 구분하는 것을 목적으로 한다. 오른쪽 손목의 센서만을 이용한 모델과 오른쪽 엄지 센서만을 이용한 모델과 둘을 같이 이용한 모델을 각각 최적화하고 성능과 이유를 분석해보았다.
주어진 데이터 셋은 각 위치당 x, y, z의 데이터가 주어졌고 train과 test셋이 나누어진 채로 제시되었다. 각 행동은 시계열 데이터로 기록되었고 한 채널당 51개의 데이터 열과 52번째 열의 라벨링으로 행동을 구분하였다. 해당 실험에서 분류하고자 하는 6가지 행동은 ‘I have command’, ‘All clear’, ‘Not clear’, ‘Spread wings’, ‘Fold wings’, ‘Lock wings’이다. 6가지 수신호의 양상을 살펴본 결과 왼쪽 손, 팔은 가만히 있는 행동이 3가지 이므로 오른쪽 손목과 엄지의 움직임 데이터를 바탕으로 모델을 구성하였다. 또한 데이터 자체적으로 train, test셋이 나누어져 있어 이를 바탕으로 실험을 진행하였고 추가적으로 validation set을 구성해 모델의 성능을 평가하고 학습하는데 이용하였다.
1) 오른쪽 손목 x축 데이터

오른쪽 손목 x축 class
그래프의 행동별 양상은 일관된 편이나 행동1,2의 경우 다른 양상을 보였다. 또한 행동 간의 양상이 유사한 경우가 있음을 확인할 수 있었다.
2) 오른쪽 손목 y축 데이터
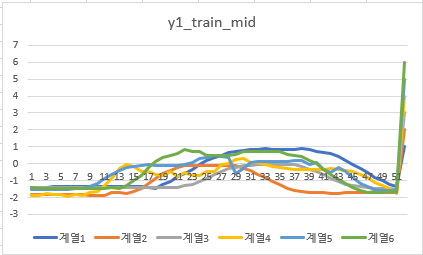
오른쪽 손목 y축 데이터
3)오른쪽 손목 z축 데이터

오른쪽 손목 z축 class
4) 오른쪽 엄지 x축 데이터

오른쪽 엄지손가락 x축 class
오른쪽 손목 데이터보다 행동간 데이터가 특정 위치에 집중되어 보인다
5) 오른쪽 엄지 y축 데이터

오른쪽 엄지손가락 y축 class
오른쪽 손목 데이터와 비슷한 양상으로 보인다.
6) 오른쪽 엄지손가락 z축 데이터

[오른쪽 엄지손가락 z축 class
오른쪽 손목 z축 데이터와 유사함을 확인할 수 있다.
- x축 데이터는 손목과 엄지 데이터에서 약간의 차이를 보였고 y축과 z축의 데이터는 거의 유사함
x,y,z의 데이터는 모두 각 행동유형 양상이 차이를 나타내는 구간 즉, 시작하는 구간과 끝나는 구간이 유사하다는 사실을 확인하였다. 행동 클래스별 차이를 보이는 부분은 데이터가 증가하거나 감소하는 부분인데 이 또한 증가하는 정도나 구간이 유사한 행동들이 존재함을 파악할 수 있었다.
손목 센서와 엄지 손가락 센서가 차이를 보이는 부분은 x축센서 데이터인데 이때 오른쪽 손목의 데이터가 x축에서 보다 상이한 행동 분포 및 유형을 보였으므로 엄지손가락 센서를 통한 classification이 손목 센서만을 이용한 classification보다 높은 정확도를 보일 것이라 예상했다. 또한, 두 센서의 데이터를 모두 이용하면 성능이 어느정도 좋아질 것으로 예측하였으나 y,z센서의 비슷한 양상을 고려하면 아주 유의미한 성능 향상은 다소 어려울 것으로 생각하였다.
3. 신경망 모델
1)오른쪽 손목 센서의 데이터만을 이용

오른쪽 손목 센서만을 이용한 모델의 실험결과 78.999% 의 정확도를 보이고 학습시간은 평균 2.1072초 소요되었다.
이 때 사용한 필터는 256, 커널 사이즈 8, relu함수를 이용하였고 class의 개수인 6을 dense층으로 사용, epoch 15와 batch사이즈 5의 모델을 이용하였다.
필터사이즈는 64보다는 128의 모델이, 128인 경우 보다 256인 모델이, 512보다는 256인 모델이 더 좋은 성능을 보였다. 아무래도 데이터의 수가 많은 편은 아니다 보니 512 이상의 필터는 학습에 방해가 되는 것으로 보인다.
커널 사이즈는 초기 임의의 보편적인 값으로 설정하였으나 데이터 양상을 확인한 이후 x축 데이터를 고려해 클래스 별 차이가 드러나는 7, 8, 10, 12, 15, 17, 20, 25 로 설정해 실험해 보았다. 커널 사이즈를 3에서 증가시켜 10까지는 정확도 78퍼센트 정도를 보였지만 15를 넘어가면서 76 퍼센트 이하로 떨어졌다.
해당 데이터는 층수가 증가하면 정확도가 떨어졌고, 풀링층 또한 추가하지 않았을 때 더 좋은 성능을 보였다. 다만 정확도만을 고려했을 때 79.552%의 정확도를 보인 모델이 있는데 이는 바로 현재 모델에 dense 512, dense 256을 추가한 모델이다. 하지만 이 모델의 경우 기존 학습시간이 2.1072 인데 반해 학습시간이 24.163 초로 약 10배 이상의 학습시간이 소요되며 소요시간에 비해 정확도 차이가 유의미하지 않다고 판단, 최적화 모델로 선택하지 않았다.
2) 오른쪽 엄지 손가락 센서 데이터만 이용한 모델

이 모델은 78.67%의 정확도와 2.62초의 학습시간을 보여주었다. 2개의 층으로 구성하였고 첫번째 층과 두번째 층 모두 필터 사이즈 32, 커널사이즈 12, activation ReLU함수를, dense 6, 풀링층은 첫 번째 층에만 추가하였다.
Epoch는 이전 실험에서와 마찬가지로 15로 설정하였는데 이는 epoch를 2배인 30으로 했을 때 정확도가 그다지 향상되지 않았고, 10으로 줄였을 때는 정확도가 크게 떨어져 15를 유지하였다.
Pooling size를 3으로 조정했을 때는0.33%정도 정확도가 감소했다. 일반적으로 층수를 늘릴 경우 커널사이즈를 줄이기에 두 번째 층의 커널사이즈를 10으로 설정해보았으나 1%정도 정확도가 감소하였다.
3) 오른쪽 손목과 엄지 손가락 데이터 모델

이 모델은 정확도 79.44%, 학습시간 1.45초의 성능을 보였다. 위의 두 모델과는 다르게 input size를 조정했다. 이 모델은 한 층의 레이어로 구성하였고 필터 32, 커널 사이즈 10, pooling층을 추가하고 epoch는 역시 15로 유지하였다.
다른 모델을 학습시킬 경우 특정 수행에서 높은 정확도를 보이고 다른 수행에서 굉장히 낮은 정확도를 보여 평균치가 중간치에서 형성되었던 것에 반해 이 모델에서는 다섯 번의 수행에서 모두 비슷하게 높은 정확성을 보여 보다 안정적으로 실험을 진행 할 수 있었다.
특히 해당 모델은 필터사이즈 512, 256, 64일 때 78중 후반 대의 정확도를 보였고 16에서 유독 성능이 저하되었다.
커널 사이즈 또한 5,10,15,20 로 설정해 수행하였고 이후 높은 성능을 보인 15와 20의 중간값으로서 17을 설정하였으니 성능이 향상되지 않았다. 커널사이즈가 10일 때 가장 좋은 정확성을 보였고 풀링층이 있을 때 학습이 더 잘 되었다.
이후 batch사이즈를 조정해보았는데 초기 설정인 8일 때 가장 정확도가 높았다.
4. 실험 및 결과 분석
예상했던 대로 두 가지 데이터를 모두 사용한 모델이 79.44%의 정확도를 보이며 가장 성능이 좋았고, x축 센서의 행동 분류가 조금 더 용이할 것으로 예측한 오른쪽 손목 데이터 최적화 모델이 78.9999%의 정확도, 오른쪽 엄지 손가락 데이터 최적화 모델이78.67%의 정확도를 보였다.
실험을 진행하면서 성능이 왜 눈에 띄게 좋아지지 않으며 80% 정확도를 맴도는지에 대해 고민해 보았는데 아무래도 데이터의 수가 아주 충분하다고 보기 어렵고, 손목 센서와 엄지손가락 센서가 대부분 비슷한 위치, 패턴으로 진행되기 때문이 아닐까 라는 결론을 내리게 되었다. 비슷한 양상으로 진행되는 두 센서이기에 다른 센서임에도 절대적인 수치상 데이터가 다르게 분포하더라도 전체적인 흐름에서 보았을 때 구분하기 어려웠던 것이 아닐지 생각해보게 되었다.
5. 결론
이 실험을 통해 여러 종류의 데이터를 같이 활용하는 모델의 성능이 좋음을 확인하였고, 데이터의 분포 및 양상을 파악하는 것이 중요하다는 것을 알게 됨

보이는 바와 같이 오른쪽 팔꿈치와 오른쪽 엄지 손가락 센서는 움직임이 상이한 경우가 많다.
추후에 이를 이용한 실험을 진행해보고 싶고 그렇다면 보다 높은 정확성을 기대해 볼 수 있을 것 같다.
6. 이를 토대로 프로젝트의 진행방향 재구성
처음에 제안한 사항을 다시 살펴보자
1. 검색어와 게시물의 사진이 관련이 있는가?
2. 게시물의 해시태그 끼리의 연관성이 있는가?
3. 검색어와 게시물에 사용된 해시태그간의 연관성이 있는가?
위의 CNN모델에서 살펴본 바와 같이 아무래도 다양한 종류의 데이터를 종합적으로 고려했을 때 정확성이 더 높게 나타남을 알 수 있었다.
이에 검색어와 이미지의 관련성 (이미지 데이터) + 게시물 내 해시태그간의 연관성 + 이미지와 해시태그의 연관성을 종합적으로 고려해 프로젝트를 진행하는 계획은 적절한 것으로 보인다.
RNN모델, 자연어 처리에 대한 공부가 더욱 필요하며 이번학기 동안 공부하고 진척된 것을 바탕으로 겨울 방학에 팀원들과 함께 보완할 생각이다.
프로젝트가 순조롭게 흘러가면 좋겠다..!