[ 졸업프로젝트🎓 ] 기술블로그 총정리
졸업프로젝트 주제는 딥러닝 기반 언택트 학습 도우미 : 자동 채점 및 오답노트 생성 이다
자동채점 기능을 구현하기 위해서는 문제집 정확히 말하면 문제 별로 데이터 베이스에 데이터를 담고있어야 하고 우리가 사용한 5개년의 수능완성, 교육청 평가원 모의고사를 일일이 추출하기는 너무 비효율적이었다.
따라서 데이터베이스를 구축하기 위해 openCV를 이용, 자동으로 문제 영역을 추출하는 기술을 구현하였다.
또한, 카메라 스캔을 통해 주관식 답안, 문제정보가 이미지로 넘어오면 이를 ocr을 거쳐 채점 알고리즘 쪽으로 넘겨주어야 한다. 스캔기능은 프론트,문제정보, 답안 추출등의 기능은 YOLO에서, 채점 기능은 백엔드에서 구현되었다. 이 글은 YOLO에서 넘어온 이미지 데이터를 읽어 text화 하고, 정렬해 백엔드로 넘겨주는 부분에 대한 설명이다.
Part1. 데이터베이스 구축 (openCV)
초기 화면 ( Input)


결과화면 (Goal)

시행착오 과정 요약
초기 아이디어
글자 있는 영역을 추출해 자르기
문제점
1. 가운데 경계를 무시하고 덩어리들 끼리 가까우면 한 영역이 되어버린다
2. 위 아래의 무늬(header, footer)가 또 다른영역으로 인식이 된다
개선 아이디어
1. 위 아래 부분을 필요한 부분 외에 crop (문제집의 형식상 위아래 여백은 크게 변하지 않는다)
2. 가운데 라인을 기준으로 왼쪽 영역, 오른쪽 영역으로 나누어서 input으로 사용한다

양쪽여백 크롭
오른쪽 중앙의 " 확률과 통계" 부분이 문제
얘도 영역으로 포함되거나 개별 영역을 차지하는 경우가 있었다.
+데이터 용량 면에서도 얼마나 유의미할지는 모르겠지만 일단 사이즈를 줄이는 부분에서 어느정도 이득이 있을것이라 판단했다.
뒤의 실전 모의고사 부분의 위 여백은 개념편 여백과 다르어서 일단은 두 파트를 모두 자르게 영역을 지정했다.
-> 크롭 자체는 이제 거의 되었으나 이게 문제 인지? 아닌지?를 판단하기 위해
pytesseract를 이용했다.
pytesseract를 통해 숫자, 한글, 영어 인식


시도한 방식은 왼쪽과 오른쪽의 크롭된 문제를 pytesseract를 이용해 인식
-> 왼쪽은 15 ~~~ 이런식으로 나오고 오른쪽은 돋보기 모양을 인식하든가 말든가,,
유형4든 뭐든간에 첫 인식된 문자 type이 int가 아니면 문제가 아니라고 판단하는 방식 -> 이 부분은 API를 이용하였다.
최종 사용방안.
과정
- 이미지 불러오기
- 문제집 위의 헤더 (문제 영역이 아닌 부분) 자르기
- 가운데 세로선 기준으로 왼쪽 오른쪽 나누기
- 문제영역 contour잡기 (왼쪽-> 오른쪽 순서)
- 각 contour의 위쪽 좌표를 이용해서 현재 contour~ 다음 contour까지 영역 잡아서 자르기 (이걸 반복)
- 헤더에서 페이지 수 읽어오기
사용한 환경은 구글 코랩이며, 데이터도 구글드라이브를 이용했다.
코드
0. 드라이브 마운트
#드라이브 마운트
from google.colab
import drive
drive.mount('/content/drive')1. & 2. 이미지 불러오기 && 윗 부분 자르기
#이미지 윗 부분 자르기
def cropTop(image):
src=cv2.imread(image)
#이미지 불러오기
#cv2_imshow(src)
dst = src.copy()
#흑백처리
gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
#canny
canny = cv2.Canny(gray, 5000, 1500, apertureSize = 5, L2gradient = True)
#min_theta=0 max_theta=np.pi/2
#허프만 이용해서 가로 직선 찾기
#220으로 되어있는 것이 임계값 : 높을수록 선명한? 직선을 검출
#min_theta :최소각도
#max_theta: 최대 각도
lines = cv2.HoughLines(canny, 0.8, np.pi / 180, 220, srn = 100, stn = 200, min_theta = 89, max_theta = 91)
#직선이 여러개 나오는데 가장 위쪽에 있는 직선을 찾으려고 miny사용
miny=700
for i in lines:
rho, theta = i[0][0], i[0][1]
#print(theta)
a, b = np.cos(theta), np.sin(theta)
x0, y0 = a*rho, b*rho
scale = src.shape[0] + src.shape[1]
x1 = int(x0 + scale * -b)
y1 = int(y0 + scale * a)
x2 = int(x0 - scale * -b)
y2 = int(y0 - scale * a)
#print("y1",y1,"y2",y2)
if (y2 < miny):
miny=y2 cv2.line(dst, (x1, y1), (x2, y2), (0, 0, 255), 2)
#cv2.circle(dst, (x0, y0), 3, (255, 0, 0), 1, cv2.FILLED)
#찾은 가로 직선 기준으로 위쪽은 header, 아래쪽은 body로 넘겨줌
header = src[:miny, :]
body=src[miny+10:,:]
#print(miny)
#cv2_imshow(body)
return header,body
3. 가운데 세로선 기준으로 왼쪽 오른쪽 나누기
<모의고사 , 평가원>
이 문제집들은 정가운데에 세로 줄이 있어서 이미지의 가로길이의 절반을 이용했다.
def cropCenter(img): src=img dst=src.copy #가로길이 w=int (img.shape[1]/2) #왼쪽 left=src[:,:w-5] #오른쪽 right=src[:,w+5:] #cv2_imshow(left) #cv2_imshow(right) contour(left) contour(right) <수능완성>
수능완성은 오른쪽 왼쪽 페이지가 있어서 세로선이 정 가운데에 있지 않다.
def cropCenter(img):
src=img
dst = src.copy()
gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
canny = cv2.Canny(gray, 5000, 1500, apertureSize = 5, L2gradient = True)
lines = cv2.HoughLines(canny, 0.8, np.pi / 180, 200, srn = 100, stn = 200, min_theta = 0, max_theta = np.pi/8)
row=0 col=0 for i in lines:
rho, theta = i[0][0], i[0][1]
a, b = np.cos(theta), np.sin(theta)
x0, y0 = a*rho, b*rho print("x0",x0,"y0",y0)
scale = src.shape[0] + src.shape[1]
x1 = int(x0 + scale * -b)
y1 = int(y0 + scale * a)
x2 = int(x0 - scale * -b)
y2 = int(y0 - scale * a)
row=x2
col=y2
cv2.line(dst, (x1, y1), (x2, y2), (0, 0, 255), 2)
#cv2.circle(dst, (x0, y0), 3, (255, 0, 0), 1, cv2.FILLED)
left = src[:, :row-15]
right= src[:,row+15:]
cv2_imshow(dst)
#contour(left)
#contour(right)위의 cropTop에서 min_theta, max_theta를 수정한것이다.
이 방법보다는 가능하면 정가운데에 직선이 있는 애들이 좋다. 왜냐면 문제속에 박스나 표가 있으면 걔네도 임계값을 넘어서는 세로 직선으로 인식되었다.

임계값을 잘 조정하면 될 것 같은데 220은 작동 잘하고 250이면 아예 아무 직선도 통과를 못하는 문제가 발생했다. 그렇기 때문에 박스가 있는 경우 여백 양쪽을 잘라내고 정가운데를 자르는 방법을 사용했다.
4. 문제 영역잡기 && 5. 문제영역 자르기
#반페이지를 입력받고 크롭하기
def contour(page_rl):
print("contour")
#이미지 흑백화
imgray = cv2.cvtColor(page_rl, cv2.COLOR_BGR2GRAY)
img2=imgray.copy()
#이미지 이진화 (스캔본 처럼)
blur = cv2.GaussianBlur(imgray, (3,3), 0)
thresh = cv2.threshold(blur, 70, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)[1]
# Morph operations
edge = cv2.Canny(imgray, 100, 200)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(1000,200))
closed = cv2.morphologyEx(edge, cv2.MORPH_CLOSE, kernel)
#문제영역 윤곽 잡기
#contours가 찾은 경계의 배열
contours, hierarchy = cv2.findContours(closed.copy(),cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours_xy = np.array(contours , dtype=object)
contours_xy.shape
#한페이지 내에서 문제 순서대로 불러오기
contours=reversed(contours)
#한페이지 내의 모든 폐곡선 범위에 대해 실행
top=[]
#폐곡선의 맨 위 x값을 담아놓는 배열 for c in contours:
#폐곡선 바운더리
x,y,w,h = cv2.boundingRect(c)
top.append(y)
total=len(top)-1
for i in range(total):
#여백이 너무 좁아서 맨위에 있는 문제 제외하고 위쪽 여백을 추가했음
#어차피_여백이 넉넉해서 괜찮
if (i==0):
img_trim=page_rl[top[i]:top[i+1]-5,:]
else:
img_trim=page_rl[top[i]-10:top[i+1]-5,:]
#cv2.imwrite('/content/MyDrive/GRADIING_Study/kh/trim/'+str(qnum)+'.png',img_trim)
#print(qnum) cv2_imshow(img_trim)6. 헤더에서 페이지 수 읽어오기
pytesseract를 사용해서

이 header의 페이지 수를 추출하려고 했으나 pystesseract가 읽어 내지 못하고 참고로 google cloud vision은 잘 읽어냄.
욜로로 잘 하면 페이지를 읽을 필요가 없어서 일단은 이렇게 마무리 하도록 했다.
이 부분은 이후 카카오 API로 해결했다.
Part2. 손글씨 및 헤더 읽기 (MNIST 이용 CNN 모델, 구글 API, 카카오 API )
MNIST 이용 CNN 모델
프로젝트 상에서 읽어야하는 글씨는 페이지 수, 페이지 상에서의 문제번호, 학생이 작성한 주관식 답안이다.
일단 주관식 답안 인식이 가장 중요했고, 여러가지 방법을 시도해보았다.
첫번째 방법은 MNIST 데이터를 이용한 CNN모델을 사용하는 것이었다.
과정
프론트에서 받아온 원본 사진을 처리해서 문제 영역 자르기-> 자른 영역에서 네모 친 답영역 추출 -> 손글씨로 쓴 답 ocr 하기
Input

MNIST 모델
#MNIST 모델
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 각종 파라메터의 영향을 보기 위해 랜덤값 고정
tf.random.set_seed(1234)
# Normalizing data
x_train, x_test = x_train / 255.0, x_test / 255.0
# (60000, 28, 28) => (60000, 28, 28, 1)로 reshape
x_train = x_train.reshape(-1, 28, 28, 1)
x_test = x_test.reshape(-1, 28, 28, 1)
# One-hot 인코딩
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
model = tf.keras.Sequential([ tf.keras.layers.Conv2D(kernel_size=(3,3), filters=64, input_shape=(28,28,1), padding='same', activation='relu'), tf.keras.layers.Conv2D(kernel_size=(3,3), filters=64, padding='same', activation='relu'), tf.keras.layers.MaxPool2D(pool_size=(2,2)), tf.keras.layers.Conv2D(kernel_size=(3,3), filters=128, padding='same', activation='relu'), tf.keras.layers.Conv2D(kernel_size=(3,3), filters=256, padding='valid', activation='relu'), tf.keras.layers.MaxPool2D(pool_size=(2,2)), tf.keras.layers.Flatten(), tf.keras.layers.Dense(units=512, activation='relu'), tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(units=256, activation='relu'), tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(units=10, activation='softmax') ])
model.compile(loss='categorical_crossentropy', optimizer=tf.optimizers.Adam(lr=0.001), metrics=['accuracy'])
model.summary()
model.fit(x_train, y_train, batch_size=100, epochs=10, validation_data=(x_test, y_test))
result = model.evaluate(x_test, y_test)
print("최종 예측 성공률(%): ", result[1]*100)
바깥 테두리 지우고 숫자영역 찾아내기
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
#이미지 읽어오기
img = cv2.imread("/content/drive/MyDrive/GRADING_Study/kh/hand/ex/788.png")
plt.figure(figsize=(15,12))
print("img")
#이미지 흑백처리
img_gray=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#이미지 블러
img_blur = cv2.GaussianBlur(img_gray, (5, 5), 0)
#이미지 내의 경계 찾기
ret, img_th = cv2.threshold(img_blur, 127, 255, cv2.THRESH_BINARY_INV) contours, hierachy= cv2.findContours(img_th.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
#경계를 직사각형으로 찾기
rects = [cv2.boundingRect(each) for each in contours]
#왼쪽에 있는 경계 순서대로 정렬
rects=sorted(rects)
thickness=abs(rects[0][2]-rects[1][2])*2
#가장 밖에 있는 경계선 찾기
contour_sizes = [(cv2.contourArea(contour), contour) for contour in contours]
biggest_contour = max(contour_sizes, key=lambda x: x[0])[1]
#찾은 경계선 흰색으로 칠하기
cv2.drawContours(img_blur, biggest_contour,-1,(255,255,255),thickness)
cv2_imshow(img_blur)
#경계선 지우고 경계 다시 찾기 : 숫자만 찾기 위해서
ret, img_th = cv2.threshold(img_blur, 127, 255, cv2.THRESH_BINARY_INV)
contours, hierachy= cv2.findContours(img_th.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) #경계 직사각형 찾기 rects = [cv2.boundingRect(each) for each in contours] #왼쪽부터 읽어와야 하므로 정렬 rects=sorted(rects) # 사각형 영역 추출 확인하기 # for rect in rects: # print(rect) # cv2.circle(img_blur, (rect[0],rect[1]),10,(0,0,255), -1) # cv2.circle(img_blur, (rect[0]+rect[2],rect[1]+rect[3]),10,(0,0,255), -1) # cv2.rectangle(img_blur,(rect[0],rect[1]),(rect[0]+rect[2],rect[1]+rect[3]),(0,255,0),3) cv2_imshow(img_blur) cv2.threshold(img, threshold_value, value, flag)
img: grayScale이고 threshold_value는 픽셀 문턱값이고 문턱값 이상이면 flag 에 따라 value로 바꿈.
flacv2.THRESH_BINARY: threshold보다 크면 value로, 작으면 0으로
cv2.THRESH_BINARY_INV: threshold보다 크면 0으로 작으면 value로
cv2.THRESH_TRUNC: threshold보다 크면 value로 지정 작으면 기존의 값 그대로 사용
cv2.THRESH_TOZERO: treshold_value보다 크면 픽셀 값 그대로 작으면 0으로
cv2.THRESH_TOZERO_INV: threshold_value보다 크면 0으로 작으면 그대로
출처: https://hoony-gunputer.tistory.com/entry/opencv-python-이미지-Thresholding [후니의 컴퓨터]
cv2.threshold(img, threshold_value, value, flag)
img: grayScale이고 threshold_value는 픽셀 문턱값이고 문턱값 이상이면 flag 에 따라 value로 바꿈.
flacv2.THRESH_BINARY: threshold보다 크면 value로, 작으면 0으로
cv2.THRESH_BINARY_INV: threshold보다 크면 0으로 작으면 value로
cv2.THRESH_TRUNC: threshold보다 크면 value로 지정 작으면 기존의 값 그대로 사용
cv2.THRESH_TOZERO: treshold_value보다 크면 픽셀 값 그대로 작으면 0으로
cv2.THRESH_TOZERO_INV: threshold_value보다 크면 0으로 작으면 그대로
출처: https://hoony-gunputer.tistory.com/entry/opencv-python-이미지-Thresholding [후니의 컴퓨터]
가장 유용하게 사용한 함수는 아래 findContours함수이다.
_, countors, _ = cv2.findContours(thr, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
이미지에서 찾는 contours와 contours의 계층 구조를 반환해줍니다. 우리는 contours에만 관심이 있기 때문에 필요없는 것들은 '_'으로 받았습니다.
thr: threshold 해준 이미지 데이터를 첫번째 인자로 집어넣는다.
cv2.RETR_TREE: 두 번째 인자는 contour 추출 모드이며, 2번째 리턴값인 hiearchy의 값에 영향을 준다.
cv2.RETR_EXTERNAL: 이미지 가장 바깥쪽의 contour만 추출
cv2.RETR_LIST: contour의 계층구조 상관관계를 고려하지 않고 contour을 추출
cv2.RETR_CCOMP: 이미지에서 모든 contour를 추출한 후, 2단계 contour 계층 구조로 구성함.
1단계 계층에서는 외곽 경계 부분을, 2단계 계층에서는 구멍(hole)의 경계 부분을 나타내는 contour러 구성됨
cv2.RETR_TREE: 이미지에서 모든 contour을 추출하고 contour들간의 상관관계를 추출함
cv2.CHAIN_APPROX_SIMPLE: 세번째 인자는 contour 근사 방법이다.
cv2.CHAIN_APPROX_NONE: contour를 추출하고 Contour들간의 상관관계를 추출함
cv2.CHAIN_APPROX_SIMPLE: contour의 수평, 수직, 대각선 방향의 점은 모두 버리고 끝점만 만겨둠
CHAIN_APPROX_TC89_L1: Teh_Chin 연결 근사 알고리즘을 적용함
출처: https://hoony-gunputer.tistory.com/entry/OpenCV-python-Contour [후니의 컴퓨터]
_, countors, _ = cv2.findContours(thr, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
이미지에서 찾는 contours와 contours의 계층 구조를 반환해줍니다. 우리는 contours에만 관심이 있기 때문에 필요없는 것들은 '_'으로 받았습니다.
thr: threshold 해준 이미지 데이터를 첫번째 인자로 집어넣는다.
cv2.RETR_TREE: 두 번째 인자는 contour 추출 모드이며, 2번째 리턴값인 hiearchy의 값에 영향을 준다.
cv2.RETR_EXTERNAL: 이미지 가장 바깥쪽의 contour만 추출
cv2.RETR_LIST: contour의 계층구조 상관관계를 고려하지 않고 contour을 추출
cv2.RETR_CCOMP: 이미지에서 모든 contour를 추출한 후, 2단계 contour 계층 구조로 구성함.
1단계 계층에서는 외곽 경계 부분을, 2단계 계층에서는 구멍(hole)의 경계 부분을 나타내는 contour러 구성됨
cv2.RETR_TREE: 이미지에서 모든 contour을 추출하고 contour들간의 상관관계를 추출함
cv2.CHAIN_APPROX_SIMPLE: 세번째 인자는 contour 근사 방법이다.
cv2.CHAIN_APPROX_NONE: contour를 추출하고 Contour들간의 상관관계를 추출함
cv2.CHAIN_APPROX_SIMPLE: contour의 수평, 수직, 대각선 방향의 점은 모두 버리고 끝점만 만겨둠
CHAIN_APPROX_TC89_L1: Teh_Chin 연결 근사 알고리즘을 적용함 출처: https://hoony-gunputer.tistory.com/entry/OpenCV-python-Contour [후니의 컴퓨터]
처음엔 cv2.RETR_TREE를 사용해서 모든 경계를 찾았다.
여기에서 사용한 217+ 동그라미이미지에 cv2.RETR_EXTERNAL을 적용하면 217+O를 하나의 덩어리로 인식해 버린다.
그러면 2,1,7,을 각각 읽어 숫자로 변환할 수가 없기 때문에 이 경계 테두리를 지우는 과정이 필요하다.
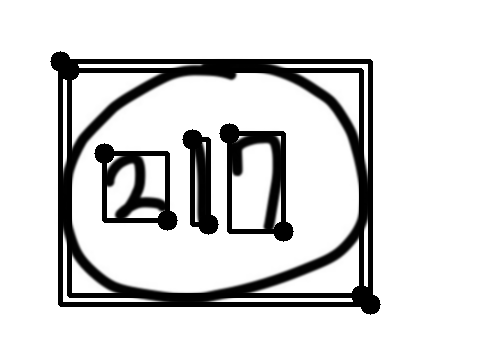
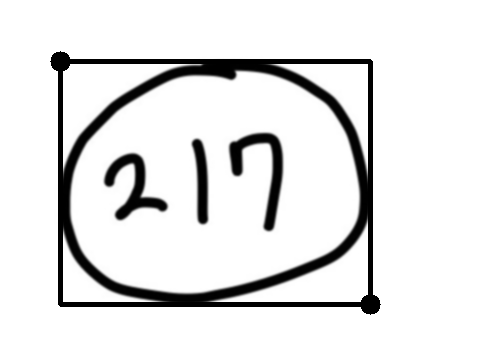
답 주위의 원 또는 네모는 안밖의 경계가 두개씩 생기는 점을 이용했다.
rects=[cv2.boundingRect(each) for each in contours] 를 통해 만들어진 경계들을 직사각형 형태로 만들었다.
rects 를 찍어보면 총 네개 의 값이 나온다.

이런식으로 나오는데 rects의 요소를 rect로 받아 살펴보면
rect[0] : 직사각형의 왼쪽 상단 점의 x 좌표
rect[1]: 직사각형의 왼쪽 상단 점의 y 좌표
rect[2]: 직사각형의 가로 길이
rect[3]: 직사각형의 세로 길이 이다.
#왼쪽에 있는 경계 순서대로 정렬
rects=sorted(rects)
thickness=abs(rects[0][2]-rects[1][2])*2 그래서 rects 를 정렬하면 rect[0]값을 기준으로 rect들이 정렬된다.

이를 이용해서 가장 바깥 테두리의 경계의 두께(thickness) 를 구한다. <= 얘를 이용해서 경계를 흰색으로 칠할 것이기 때문!
rects의 요소의 세로길이 차를 이용했다. 그리고 두께가 균일하지 않을 것을 고려해 차의 2배를 두께로 설정한다.
#가장 밖에 있는 경계선 찾기
contour_sizes = [(cv2.contourArea(contour), contour) for contour in contours]
biggest_contour = max(contour_sizes, key=lambda x: x[0])[1](contour들의 넓이, contour)로 contour_sizes의 배열을 구성한다. 딕셔너리 처럼 쓰는 방식
contour_sizes 중 contour 넓이(x[0])를 키값으로 사용해 넓이가 가장 큰 폐곡선(max(여기서 찾은 x)의 [1]) 을 이용한다.
#찾은 경계선 흰색으로 칠하기 cv2.drawContours(img_blur, biggest_contour,-1,(255,255,255),thickness) cv2_imshow(img_blur)img_blur 라는 이미지에 위에서 구한 가장 바깥 경계인 biggest_contour의 전체(-1을 이용) 를 흰색(255,255,255)으로, 그리고 두께는 위에서 구한 두께(thickness) 로 칠한다.
결과는 다음과 같다.
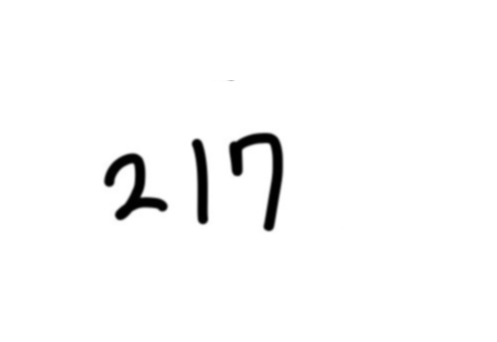
이제 이 이미지를 바탕으로 다시 숫자 박스들을 찾고, MNIST 모델로 숫자를 예측하면 된다.
MNIST train, test 데이터는 사이즈가 (-1,28,28,1)로 정해져있다.
위 이미지를 추출하면 사이즈가 제각각이다.
#경계선 지우고 경계 다시 찾기 : 숫자만 찾기 위해서
ret, img_th = cv2.threshold(img_blur, 127, 255, cv2.THRESH_BINARY_INV)
contours, hierachy= cv2.findContours(img_th.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
#경계 직사각형 찾기
rects = [cv2.boundingRect(each) for each in contours]
#왼쪽부터 읽어와야 하므로 정렬
rects=sorted(rects)주석처리한 부분을 해제하고 실행해보면



추출한 숫자영역 MNIST 돌리기 전처리
from google.colab.patches import cv2_imshow
#이전에 처리해놓은 이미지 사용
img_for_class = img_blur.copy()
#최종 이미지 파일용 배열
mnist_imgs=[] margin_pixel = 15
#숫자 영역 추출 및 (28,28,1) reshape
for rect in rects:
print(rect)
#숫자영역 추출
im=img_for_class[rect[1]-margin_pixel:rect[1]+rect[3]+margin_pixel,rect[0]-margin_pixel:rect[0]+rect[2]+margin_pixel]
row, col = im.shape[:2]
#정방형 비율을 맞춰주기 위해 변수 이용
bordersize= max(row,col)
diff=min(row,col)
#이미지의 intensity의 평균을 구함
bottom = im[row-2:row, 0:col]
mean = cv2.mean(bottom)[0]
# border추가해 정방형 비율로 보정
border = cv2.copyMakeBorder( im, top=0, bottom=0, left=int((bordersize-diff)/2), right=int((bordersize-diff)/2), borderType=cv2.BORDER_CONSTANT, value=[mean, mean, mean] )
square=border cv2_imshow(square)
#square 사이즈 (28,28)로 축소
resized_img=cv2.resize(square,dsize=(28,28),interpolation=cv2.INTER_AREA)
mnist_imgs.append(resized_img)
cv2_imshow(resized_img)
이 부분이 가장 애를 먹었던 부분이다 🤨
처음에 단순하게 숫자영역을 추출하면 비율이 제각각이다.
예를들어 3을 손글씨로 쓰게되면 대충 가로:세로의 비율이 55:100 정도라 할때 reshape로 비율을 무시하고 (28,28)로 맞춰버리니까
굉장히 찌그러진 3이 된다. 결국 MNIST CNN 모델에 돌려도 제대로 읽지 못했다.
하지만 비율을 미리 맞추고 reshape를 하니 CNN모델이 문제없이 작동했다.

숫자 이미지 모델 이용해 예측해보기
for i in range(len(mnist_imgs)):
img = mnist_imgs[i] cv2_imshow(img)
# 이미지를 784개 흑백 픽셀로 사이즈 변환
img=img.reshape(-1, 28, 28, 1)
# 데이터를 모델에 적용할 수 있도록 가공
input_data = ((np.array(img) / 255) - 1) * -1 input_data
# 클래스 예측 함수에 가공된 테스트 데이터 넣어 결과 도출
res = np.argmax(model.predict(input_data), axis=-1)
print(res)

이에 손글씨는 CNN모델을 사용하려고 거의 결정을 했었다.
하지만 읽어야 할 데이터가 주관식 답안은 확실히 결정되었다가 아무래도 한글, 영어, 숫자+"." (ex. 1. 2. 3.) 이 추가되어서 이 모델은 일단 이식은 보류해두고 API부분을 다시 알아보았다.
MNIST 모델은 숫자만을 인식 가능하고 경계 처리도 완벽하게 되기를 기대하기는 어렵기 때문도 있다.
모델을 쓰면 더 좋았겠지만 이 과정에서도 많이 배워서 크게 아쉽진 않았다.
그렇게 Google vision API와 카카오 vision API를 알아보았다.
조사를 해보니 구글은 비용이 꽤 많이 발생하였다. 흐린글씨나 경계가 있는 이미지의 정확도는 카카오와 구글이 유사했다. 사실 기울어진 이미지에 대해서는 카카오가 조금 더 높은 정확도를 보이고, 리턴해주는 json 형식도 우리 프로젝트에 더 부합했다.
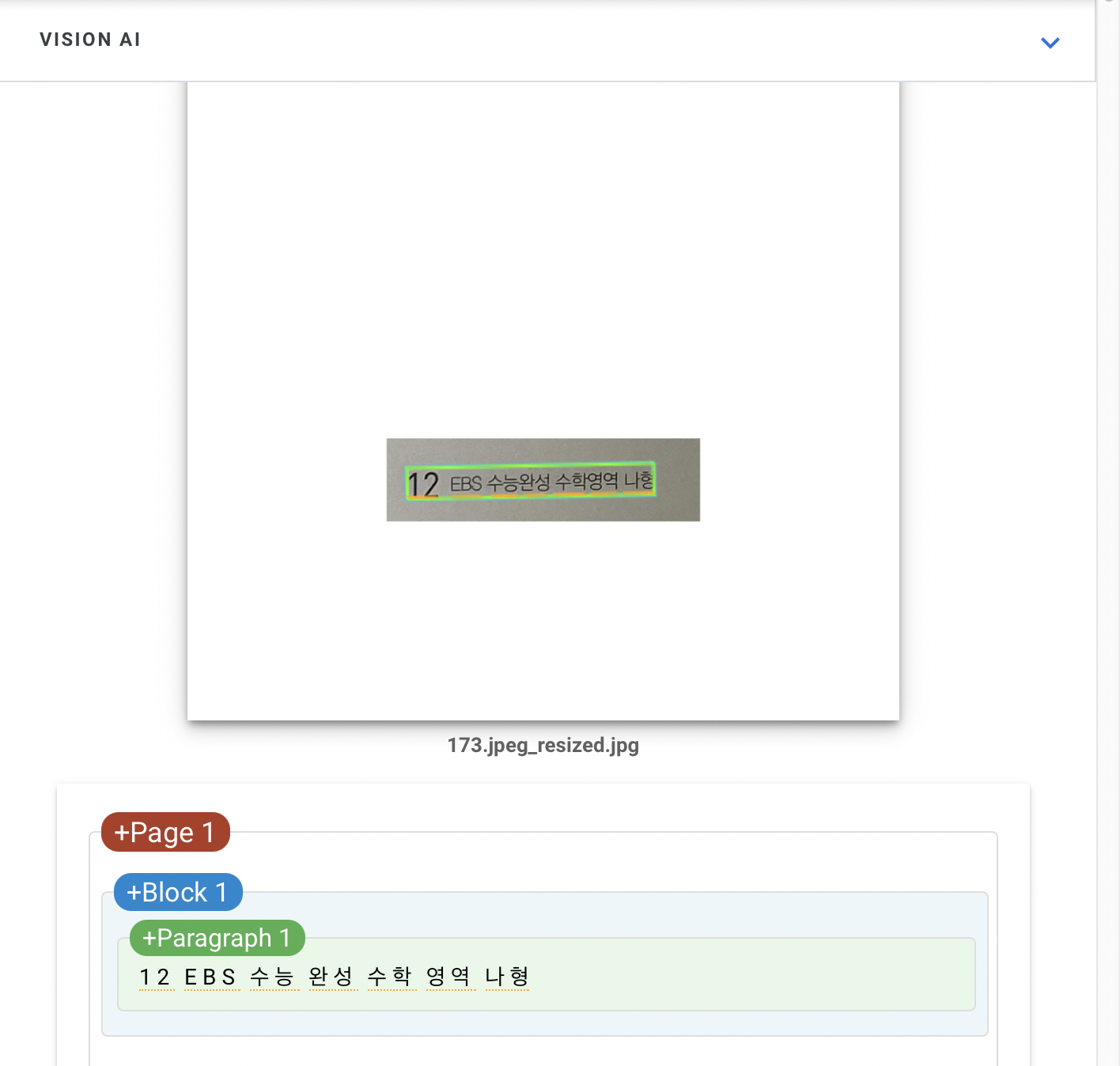

실제 추출영역인데 현 프로젝트에서는 전체의 text보다 페이지 영역인 숫자를 필요로 하기 때문이다.
이에 카카오 API를 선택하였다.
사용할 이미지

결과 화면
[OCR] output:{ "result": [ { "boxes": [ [ 132, 249 ], [ 177, 249 ], [ 177, 288 ], [ 132, 288 ] ], "recognition_words": [ "12" ] }, { "boxes": [ [ 196, 254 ], [ 244, 253 ], [ 244, 277 ], [ 196, 278 ] ], "recognition_words": [ "EBS" ] }, { "boxes": [ [ 250, 252 ], [ 343, 252 ], [ 343, 278 ], [ 250, 278 ] ], "recognition_words": [ "수능완성" ] }, { "boxes": [ [ 352, 250 ], [ 446, 246 ], [ 448, 274 ], [ 354, 279 ] ], "recognition_words": [ "수학영역" ] }, { "boxes": [ [ 456, 248 ], [ 502, 248 ], [ 502, 274 ], [ 456, 274 ] ], "recognition_words": [ "나형" ] } ] }
전체 코드
import json
import time
import cv2
import requests
import sys
from google.colab.patches import cv2_imshow
LIMIT_PX = 1024
LIMIT_BYTE = 1024*1024 # 1MB
LIMIT_BOX = 40
def kakao_ocr_resize(image_path: str):
"""
ocr detect/recognize api helper
ocr api의 제약사항이 넘어서는 이미지는 요청 이전에 전처리가 필요.
pixel 제약사항 초과: resize
용량 제약사항 초과 : 다른 포맷으로 압축, 이미지 분할 등의 처리 필요. (예제에서 제공하지 않음)
:param image_path: 이미지파일 경로
:return:
"""
image = cv2.imread(image_path)
height, width, _ = image.shape
if LIMIT_PX < height or LIMIT_PX < width:
ratio = float(LIMIT_PX) / max(height, width)
image = cv2.resize(image, None, fx=ratio, fy=ratio)
height, width, _ = height, width, _ = image.shape
# api 사용전에 이미지가 resize된 경우, recognize시 resize된 결과를 사용해야함.
image_path = "{}_resized.jpg".format(image_path)
cv2.imwrite(image_path, image)
return image_path
return None
def kakao_ocr(image_path: str, appkey: str):
"""
OCR api request example
:param image_path: 이미지파일 경로
:param appkey: 카카오 앱 REST API 키
"""
API_URL = 'https://dapi.kakao.com/v2/vision/text/ocr'
headers = {'Authorization': 'KakaoAK {}'.format(appkey)}
image = cv2.imread(image_path)
jpeg_image = cv2.imencode(".jpg", image)[1]
data = jpeg_image.tobytes()
return requests.post(API_URL, headers=headers, files={"image": data})
def main():
if len(sys.argv) != 3:
print("Please run with args: $ python example.py /path/to/image appkey")
image_path, appkey = '/content/drive/MyDrive/ts/swpg.png', '발급받은 APP키'
white = [255,255,255]
img=cv2.imread(image_path)
constant= cv2.copyMakeBorder(img,200,100,100,100,cv2.BORDER_CONSTANT,value=white)
image_path='/content/drive/MyDrive/ts/swpg.jpg'
cv2.imwrite(image_path, constant)
cv2_imshow(constant)
time.sleep(2)
resize_impath = kakao_ocr_resize(image_path)
if resize_impath is not None:
image_path = resize_impath
print("원본 대신 리사이즈된 이미지를 사용합니다.")
output = kakao_ocr(image_path, appkey).json()
print("[OCR] output:\n{}\n".format(json.dumps(output, sort_keys=True,ensure_ascii=False, indent=2)))
if __name__ == "__main__":
main()
다른 부분은 카카오 api 코드를 그대로 사용한 것이고 바꾼 부분은 main 쪽이다.
def main():
if len(sys.argv) != 3:
print("Please run with args: $ python example.py /path/to/image appkey")
image_path, appkey = '이미지 경로', '발급받은 APP키'
# 이미지 크기 조절
white = [255,255,255]
img=cv2.imread(image_path)
constant= cv2.copyMakeBorder(img,200,100,100,100,cv2.BORDER_CONSTANT,value=white)
#생성한 jpg경로에 저장하고 경로 초기화
image_path='/content/drive/MyDrive/ts/swpg.jpg'
cv2.imwrite(image_path, constant)
cv2_imshow(constant) time.sleep(2)
resize_impath = kakao_ocr_resize(image_path)
if resize_impath is not None:
image_path = resize_impath
print("원본 대신 리사이즈된 이미지를 사용합니다.")
output = kakao_ocr(image_path, appkey).json()
print("[OCR] output:\n{}\n".format(json.dumps(output, sort_keys=True,ensure_ascii=False, indent=2))) 그냥 이미지를 넣으면 이미지가 작은 경우, 읽지를 못해서 주어진 이미지에 경계를 임의로 추가해주었다.
원래는 흑백처리를 하고 넣어서 흰색이 티가 별로 나지 않았는데 , 그리고 티가 나면 새로운 경계로 인식할까봐 걱정했는데 input이미지가

인식을 잘했다.
그리고 json파일을 읽어올 때

이렇게 한글을 못하는 경우가 있어서 아래와 같이 수정했다.
# 기본코드에 ensure_ascii=False 를 추가 print("[OCR] output:\n{}\n".format(json.dumps(output, sort_keys=True,ensure_ascii=False, indent=2)))
찾아보니 api를 다들 html이나 이미 존재하는 서비스에 도입한 것 같던데, 우린 아직 로컬/코랩에서 사용해야해서 경로를 직접지정하고 아웃풋을 json파일이 아닌 프린트로 받았다.
이렇게 데이터베이스 구축과 ocr 파트를 성공적으로 마무리했다. :)