지금까지 다룬 것은 고정 크기 데이터에 관한 내용이었는데 이 고정 길이 모델로 충분하지 않을 때가 많다.
만약 시퀀스 분석을 하기 위해 전방향 신경망을 이용한다면?
1) 시퀀스가 입력층과 동일한 크기라면
→ 적절하게 작동
2) 시퀀스 < 입력층이면
→ 적절한 길이가 될 때까지 0을 이어 추가해서 이용가능
3) 시퀀스 > 입력층 이면
→ 모델이 망가져 버림

<텍스트 본문을 처리하고 품사 태그의 시퀀스를 생성하는 전방향 신경망 구조>
= 입력된 텍스트에서 명사, 동사, 전치사 등으로 단어를 표시
대화가 가능한 수준까지는 아니지만 이 과정이 한 문장에서 단어가 사용되는 방식의 의미를 이해할 수 있는 알고리즘 개발을 향한 첫 단계
이 문제의 목표는 입력 시퀀스를 각각 해당하는 출력 시퀀스로 변환하는 것이다.
또한 이 문제는 seq2seq 문제 의 한 예이다.

seq2seq 문제
Sequence-to-Sequence 는 번역기에서 대표적으로 사용되는 모델로 [인코더, 디코더] 2개의 아키텍처로 구성된다.
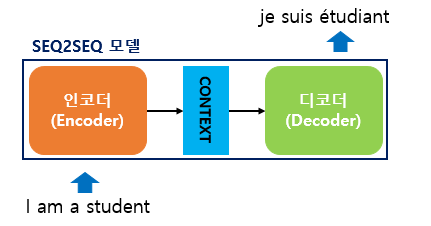
인코더
입력 문장의 모든 단어를 차례대로 입력 받은 뒤에 최종적으로 모든 단어 정보들을 압축해 하나의 벡터로 만듦
▶ 컨텍스트 벡터(context vector)
디코더
컨텍스트 벡터를 인코더로 부터 받아서 번역된 단어를 순차적으로 출력
ex)언어간 텍스트 번역과 텍스트 요약, 음성을 텍스트로 옮기기 등이 있다.
seq2seq 방식의 핵심은 주어진 어떤 단어의 품사를 예측 하려고 장기 의존성을 고려할 필요가 없다는 것.
모든 품사 태그를 예측할 때
전체 시퀀스를 이용하는 대신 고정 길이 부분 시퀀스를 사용해 각 품사태그를 한 번에 하나씩 예측할 수 있다.
특히, 관심 단어에서 시작해서 뒤로 N개의 단어를 확장하는 부분 시퀀스를 사용한다.
입력의 i번째 단어에 대한 품사를 예측 할때 i-(n-1)번째, i-(n-2) 번째 .... i번째 단어를 입력으로 사용한다.
이렇게 사용되는 부분 시퀀스를 문맥 윈도(content window)라 한다.
seq2seq의 과정을 단계별로 살펴보면

이를 구현하는 단계로 넘어가 보자.
우선 안됫 하차함 ㅅㄱ
<의존 구문 분석 트리 만들기>
제시된 'I took a taxi to the airport' 를 살펴보자
문장 속에서 'I'는 주어, 'took'은 서술어 'taxi'는 동사의 직접 목적어이다.

'🎸 > 딥러닝' 카테고리의 다른 글
| 데이터 별 CNN 최적화 모델-NATOPS database 3 Sensor (0) | 2020.11.25 |
|---|---|
| [딥러닝의 정석] 신경망 (1장 - 1: 신경망 필요한 개념 정리) (0) | 2020.07.08 |